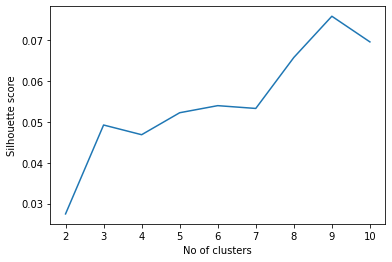
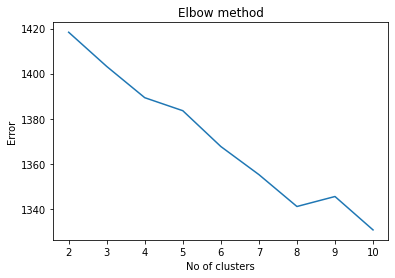
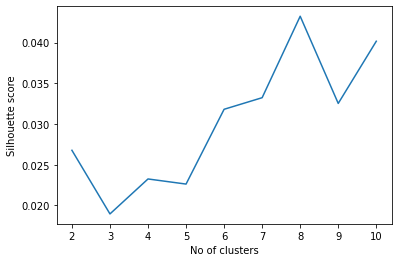
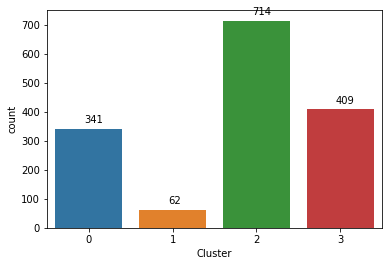
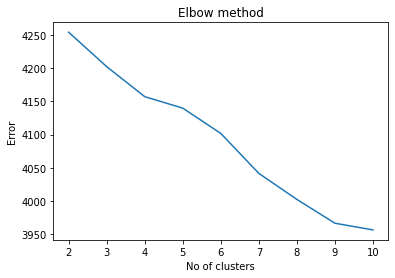
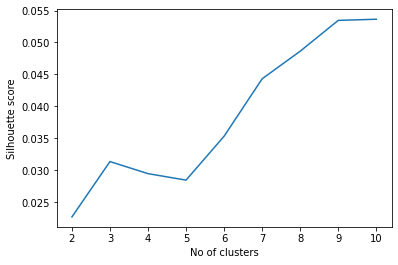
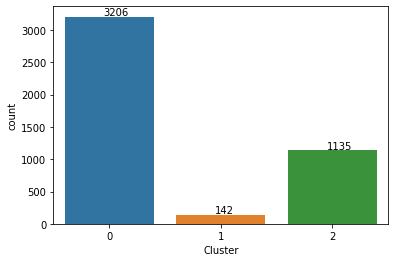
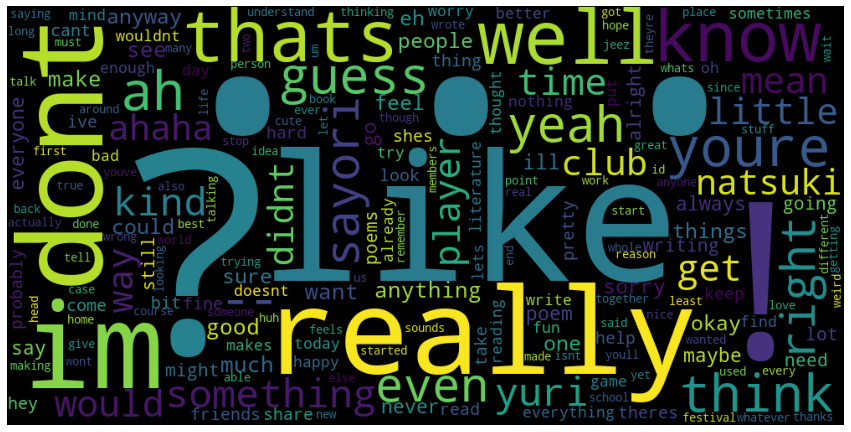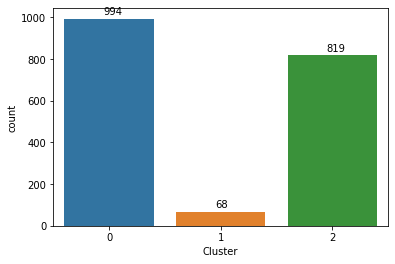[('...', 385),
('!', 309),
('?', 166),
('player', 75),
('im', 60),
('like', 56),
('really', 55),
('thats', 49),
('dont', 49),
('know', 46),
('youre', 28),
('ehehe', 27),
('well', 25),
('get', 25),
('--', 25),
('ehehe~', 24),
('everyone', 24),
('eh', 23),
('right', 23),
('happy', 22),
('even', 21),
('good', 21),
('okay', 21),
('would', 20),
('want', 19),
('club', 19),
('make', 19),
('monika', 19),
('think', 19),
('much', 19),
('time', 18),
('little', 18),
('come', 18),
('poem', 18),
('fun', 16),
('go', 16),
('best', 15),
('na', 15),
('one', 14),
('see', 14),
('gon', 14),
('say', 13),
('way', 13),
('sorry', 13),
('feelings', 13),
('wouldnt', 13),
('mean', 12),
('guess', 12),
('yeah', 12),
('natsuki', 12),
('poems', 12),
('nice', 12),
('thing', 12),
('ah', 12),
('always', 11),
('something', 11),
('ahaha', 11),
('understand', 11),
('maybe', 11),
('things', 11),
('everything', 10),
('hey', 10),
('cant', 10),
('people', 10),
('every', 10),
('going', 10),
('feel', 10),
('though', 10),
('else', 10),
('sometimes', 9),
('could', 9),
('yuri', 9),
('worry', 9),
('today', 9),
('us', 9),
('better', 9),
('try', 8),
('kind', 8),
('made', 8),
('wanted', 8),
('friends', 8),
('/i', 8),
('love', 8),
('nothing', 8),
('tell', 8),
('bad', 8),
('bit', 8),
('it~', 8),
('didnt', 8),
('anything', 8),
('ever', 8),
('thinking', 7),
('thought', 7),
('keep', 7),
('please', 7),
('new', 7),
('oh', 7),
('first', 7),
('makes', 7),
('day', 7)]